python string
第二次世界大战促使了现代电子计算机的诞生,世界上的第一台通用电子计算机叫 ENIAC(电子数值积分计算机),诞生于美国的宾夕法尼亚大学,占地 167 平米,重量 27 吨,每秒钟大约能够完成约 5000 次浮点运算,如下图所示。ENIAC 诞生之后被应用于导弹弹道的计算,而数值计算也是现代电子计算机最为重要的一项功能
# 字符串的定义
所谓字符串,就是由零个或多个字符组成的有限序列,一般记为:
在 Python 程序中,如果我们把单个或多个字符用单引号或者双引号包围起来,就可以表示一个字符串。字符串中的字符可以是特殊符号、英文字母、中文字符、日文的平假名或片假名、希腊字母、Emoji 字符等。
1 | s1 = 'hello, world!' |
提示:
end=''表示输出后不换行,即将默认的结束符\n(换行符)更换为''(空字符)。
# 转义字符和原始字符串
可以在字符串中使用 \ (反斜杠)来表示转义,也就是说 \ 后面的字符不再是它原来的意义,例如: \n 不是代表反斜杠和字符 n ,而是表示换行; \t 也不是代表反斜杠和字符 t ,而是表示制表符。所以如果字符串本身又包含了 ' 、 " 、 \ 这些特殊的字符,必须要通过 \ 进行转义处理。例如需要一个带单引号或反斜杠的字符串,可以用如下所示的方法进行处理。
1 | # 头尾带单引号的hello, world! |
Python 中的字符串可以 r 或 R 开头,这种字符串被称为原始字符串,意思是字符串中的每个字符都是它本来的含义,没有所谓的转义字符。例如,在字符串 'hello\n' 中, \n 表示换行;而在 r'hello\n' 中, \n 不再表示换行,就是反斜杠和字符 n 。大家可以运行下面的代码,看看会输出什么。
1 | # 字符串s1中\t是制表符,\n是换行符 |
Python 中还允许在 \ 后面还可以跟一个八进制或者十六进制数来表示字符,例如 \141 和 \x61 都代表小写字母 a ,前者是八进制的表示法,后者是十六进制的表示法。另外一种表示字符的方式是在 \u 后面跟 Unicode 字符编码,例如 \u9a86\u660a 代表的是中文 “小明”。运行下面的代码,看看输出了什么。
1 | s1 = '\141\142\143\x61\x62\x63' |
# 字符串的运算
Python 为字符串类型提供了非常丰富的运算符,我们可以使用 + 运算符来实现字符串的拼接,可以使用 * 运算符来重复一个字符串的内容,可以使用 in 和 not in 来判断一个字符串是否包含另外一个字符串,我们也可以用 [] 和 [:] 运算符从字符串取出某个字符或某些字符。
# 拼接和重复
下面的例子演示了使用 + 和 * 运算符来实现字符串的拼接和重复操作。
1 | s1 = 'hello' + ' ' + 'world' |
用 * 实现字符串的重复是非常有意思的一个运算符,在很多编程语言中,要表示一个有 10 个 a 的字符串,你只能写成 "aaaaaaaaaa" ,但是在 Python 中,你可以写成 'a' * 10 。你可能觉得 "aaaaaaaaaa" 这种写法也没有什么不方便的,那么想一想,如果字符 a 要重复 100 次或者 1000 次又会如何呢?
# 比较运算
对于两个字符串类型的变量,可以直接使用比较运算符比较两个字符串的相等性或大小。需要说明的是,因为字符串在计算机内存中也是以二进制形式存在的,那么字符串的大小比较比的是每个字符对应的编码的大小。例如 A 的编码是 65 , 而 a 的编码是 97 ,所以 'A' < 'a' 的结果相当于就是 65 < 97 的结果,很显然是 True ;而 'boy' < 'bad' ,因为第一个字符都是 'b' 比不出大小,所以实际比较的是第二个字符的大小,显然 'o' < 'a' 的结果是 False ,所以 'boy' < 'bad' 的结果也是 False 。如果不清楚两个字符对应的编码到底是多少,可以使用 ord 函数来获得,例如 ord('A') 的值是 65 ,而 ord('明') 的值是 26122 。下面的代码为大家展示了字符串的比较运算。
1 | s1 = 'a whole new world' |
需要强调一下的是,字符串的比较运算比较的是字符串的内容,Python 中还有一个 is 运算符(身份运算符),如果用 is 来比较两个字符串,它比较的是两个变量对应的字符串是否在内存中相同的位置(内存地址),简单的说就是两个变量是否对应内存中的同一个字符串。看看下面的代码就比较清楚 is 运算符的作用了。
1 | s1 = 'hello world' |
# 成员运算
Python 中可以用 in 和 not in 判断一个字符串中是否存在另外一个字符或字符串, in 和 not in 运算通常称为成员运算,会产生布尔值 True 或 False ,代码如下所示。
1 | s1 = 'hello, world' |
# 获取字符串长度
获取字符串长度没有直接的运算符,而是使用内置函数 len ,我们在上节课的提到过这个内置函数,代码如下所示。
1 | s1 = 'hello, world' |
# 索引和切片
如果希望从字符串中取出某个字符,我们可以对字符串进行索引运算,运算符是 [n] ,其中 n 是一个整数,假设字符串的长度为 N ,那么 n 可以是从 0 到 N-1 的整数,其中 0 是字符串中第一个字符的索引,而 N-1 是字符串中最后一个字符的索引,通常称之为正向索引;在 Python 中,字符串的索引也可以是从 -1 到 -N 的整数,其中 -1 是最后一个字符的索引,而 -N 则是第一个字符的索引,通常称之为负向索引。注意,因为字符串是不可变类型,所以不能通过索引运算修改字符串中的字符。
1 | s1 = 'abc123456' |
需要提醒大家注意的是,在进行索引操作时,如果索引越界(正向索引不在 0 到 N-1 范围,负向索引不在 -1 到 -N 范围),会引发 IndexError 异常,错误提示信息为: string index out of range (字符串索引超出范围)。
如果要从字符串中取出多个字符,我们可以对字符串进行切片,运算符是 [i:j:k] ,其中 i 是开始索引,索引对应的字符可以取到; j 是结束索引,索引对应的字符不能取到; k 是步长,默认值为 1 ,表示从前向后获取相邻字符的连续切片,所以 :k 部分可以省略。假设字符串的长度为 N ,当 k > 0 时表示正向切片(从前向后获取字符),如果没有给出 i 和 j 的值,则 i 的默认值是 0 , j 的默认值是 N ;当 k < 0 时表示负向切片(从后向前获取字符),如果没有给出 i 和 j 的值,则 i 的默认值是 -1 ,j 的默认值是 -N - 1 。如果不理解,直接看下面的例子,记住第一个字符的索引是 0 或 -N ,最后一个字符的索引是 N-1 或 -1 就行了。
1 | s1 = 'abc123456' |
# 循环遍历
如果希望从字符串中取出每个字符,可以使用 for 循环对字符串进行遍历,有两种方式。
方式一:
1 | s1 = 'hello' |
方式二:
1 | s1 = 'hello' |
# 字符串的方法
在 Python 中,我们可以通过字符串类型自带的方法对字符串进行操作和处理,对于一个字符串类型的变量,我们可以用 变量名.方法名() 的方式来调用它的方法。所谓方法其实就是跟某个类型的变量绑定的函数,后面我们讲面向对象编程的时候还会对这一概念详加说明。
# 大小写相关操作
下面的代码演示了和字符串大小写变换相关的方法。
1 | s1 = 'hello, world!' |
# 查找操作
如果想在一个字符串中查找有没有另外一个字符串,可以使用字符串的 find 或 index 方法。
1 | s1 = 'hello, world!' |
在使用 find 和 index 方法时还可以通过方法的参数来指定查找的范围,也就是查找不必从索引为 0 的位置开始。 find 和 index 方法还有逆向查找(从后向前查找)的版本,分别是 rfind 和 rindex ,代码如下所示。
1 | s = 'hello good world!' |
# 性质判断
可以通过字符串的 startswith 、 endswith 来判断字符串是否以某个字符串开头和结尾;还可以用 is 开头的方法判断字符串的特征,这些方法都返回布尔值,代码如下所示。
1 | s1 = 'hello, world!' |
# 格式化字符串
在 Python 中,字符串类型可以通过 center 、 ljust 、 rjust 方法做居中、左对齐和右对齐的处理。
1 | s1 = 'hello, world' |
我们之前讲过,在用 print 函数输出字符串时,可以用下面的方式对字符串进行格式化。
1 | a = 321 |
当然,我们也可以用字符串的方法来完成字符串的格式,代码如下所示。
1 | a = 321 |
从 Python 3.6 开始,格式化字符串还有更为简洁的书写方式,就是在字符串前加上 f 来格式化字符串,在这种以 f 打头的字符串中, {变量名} 是一个占位符,会被变量对应的值将其替换掉,代码如下所示。
1 | a = 321 |
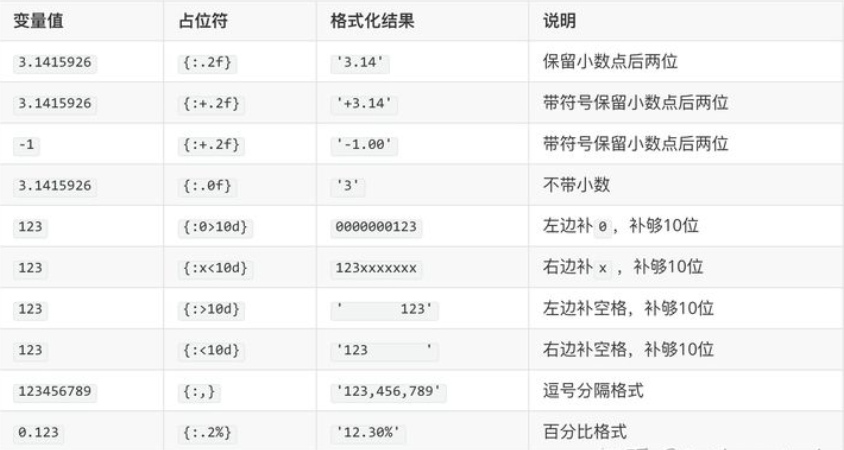
如果需要进一步控制格式化语法中变量值的形式,可以参照下面的表格来进行字符串格式化操作。
# 修剪操作
字符串的 strip 方法可以帮我们获得将原字符串修剪掉左右两端空格之后的字符串。这个方法非常有实用价值,通常用来将用户输入中因为不小心键入的头尾空格去掉, strip 方法还有 lstrip 和 rstrip 两个版本,相信从名字大家已经猜出来这两个方法是做什么用的。
1 | s1 = ' jackfrued@126.com \t\r\n' |
# 其他方法
除了上面讲到的方法外,字符串类型还有很多方法,如拆分、合并、编码、解码等,这些方法等我们用到的时候再为大家进行续点讲解。对于字符串类型来说,还有一个常用的操作是对字符串进行匹配检查,即检查字符串是否满足某种特定的模式。例如,一个网站对用户注册信息中用户名和邮箱的检查,就属于模式匹配检查。实现模式匹配检查的工具叫做正则表达式,Python 语言通过标准库中的 re 模块提供了对正则表达式的支持,我们会在后续的课程中为大家讲解这个知识点。
# 简单的总结
知道如何表示和操作字符串对程序员来说是非常重要的,因为我们需要处理文本信息,Python 中操作字符串可以用拼接、切片等运算符,也可以使用字符串类型的方法。
 wechat
wechat alipay
alipay